



智能驾驶带动了全国范围内大大小小的试验园区,产生了庞大的产业。智能驾驶代表着顶尖科技人才的聚拢,也代表吸引资本的宠爱,车企不断推高智能驾驶的声量,谁的声音大谁就享有相当可观的话语权。
然而一个新兴产业的兴衰,显然不是用户最关心的,甚至有用户会反感这门大生意。
那么问题来了,如何一边抓产业,一边抓住用户的心?

关于部分人群对智能驾驶的反感,一线主流智能车企似乎已经找到了完美的解决之道:把智驾与主动安全进行绑定。
这种绑定并非表面文章,例如智驾领域不断升级的AEB,或者针对“前车消失场景”研发的主动避让,都是在解决安全问题,而非炫技。
早期,智驾一线队伍中并没有理想汽车。而今,时机似乎已然成熟,理想All-in的态度也拿出来了。
「无图NOA」全量推送
7月5日,理想汽车召开2024智能驾驶夏季发布会,宣布于7月内向理想AD Max用户全量推送「无图NOA」,并打出“全国都能开”的Slogan。此外,推送功能还包含全自动AES自动紧急转向、全方位低速AEB自动紧急制动。
同时,理想汽车发布了基于端到端模型、VLM视觉语言模型和世界模型的全新自动驾驶技术架构,并开启新架构的早鸟计划。

5-6月期间,「无图NOA」已经陆续展开体验,规模陆续扩大。
事实上,对于理想智驾部门的技术控来说,“无图NOA”并不是一个贴切的功能描述,而在行业中这个词汇已经普及,再创一个新名称的意义也就不大了。
无图NOA不再依赖数月更新一次的高精地图,支持在全国范围内广泛的区域使用,借助理想的时空联合规划能力,丝滑的绕行体验让人印象深刻。无图NOA具备超远视距的导航选路能力,具备分米级微操能力(例如主动避让),能够适用于复杂路口。
另外,即将推送的AES自动紧急转向可实现全自动触发,不依赖人工辅助扭力;全方位低速AEB再度拓展存在主动安全风险的场景,能够减少低速挪车场景下的剐蹭事故风险。

发布会中,理想汽车产品部高级副总裁范皓宇表示:
“理想汽车已经在全国各城市积累了超100万公里的无图NOA行驶里程,全量推送后,24万名理想AD Max车主都将用上当前国内领先的智能驾驶产品。”
接下来,无图NOA将主要在4项重大能力方面进行升级。

首先,基于感知、理解和道路结构构建能力的提升,无图NOA能够摆脱对先验信息的依赖。全国范围内,导航覆盖的区域均支持NOA,胡同窄路和乡村小路也可以开启功能。
其次,基于“时空联合规划”,车辆对道路障碍物的避让、绕行将更加丝滑。通过持续预测与他车的空间关系,时空联合规划能够规划合理的可行驶轨迹。基于海量样本学习,系统能快速筛选轨迹,果断且保证安全地执行绕行操作。
复杂城市路口场景下,无图NOA的选路能力也得到显著提升,基于BEV视觉模型+导航匹配算法,系统支持实时感知变化的路沿、路面箭头标识、路口特征,并将车道结构和导航特征充分融合。
通过激光雷达+视觉融合,系统可识别更大范围内的不规则障碍物,感知精度也更高,从而对其他交通参与者实现更早、更准的预判。车辆能与其他交通参与者保持合理距离,加速减速的时机也将更加得当。

主动安全不分,理想汽车建立了完善的“安全风险场景库”,根据频次和危险程度进行分类,以提升风险场景覆盖度。
车速度较快时,主动安全系统的反应时机很短,部分情况下即使触发AEB也难以及时刹停。为了应对AEB无法规避的“物理极限场景”,理想推出了全自动触发的AES自动紧急转向。
针对泊车和低速行车场景,全方位低速AEB能够提供360度主动安全防护,在相对复杂的地库环境,全方位低速AEB能够有效识别前、后、侧向的碰撞风险,及时紧急制动。
端到端模型+VLM视觉语言模型
全新的智驾架构由端到端模型、VLM视觉语言模型和世界模型共同构成。
端到端模型主要用于处理常规驾驶行为,传感器输入到行驶轨迹输出,只经过一个模型,信息传递、推理计算、模型迭代更高效,驾驶行为也更拟人。
VLM视觉语言模型具备强大的逻辑思考能力,能够理解导航地图、复杂路况和交通规则,以应对未知场景。同时,系统将在基于世界模型构建的场景中进行学习和测试。构建的测试场景,既符合人类世界的真实规律,也具备强大的泛化能力。

理想汽车的全新智驾驶技术架构,一定程度上受到诺贝尔奖得主丹尼尔·卡尼曼的「快慢系统理论」启发,善于模拟人类的思考与决策,形成更拟人的解决方案。
新架构分为快系统与慢系统:
快系统:善于处理简单的任务,类似人类的直觉,应对覆盖95%的常规场景。
慢系统:类似人类深入的理解与学习,形成复杂的逻辑和计算,用于解决复杂未知的5%场景。
快系统与慢系统配合,确保大部分场景下的高效率,和少数场景下的高上限。
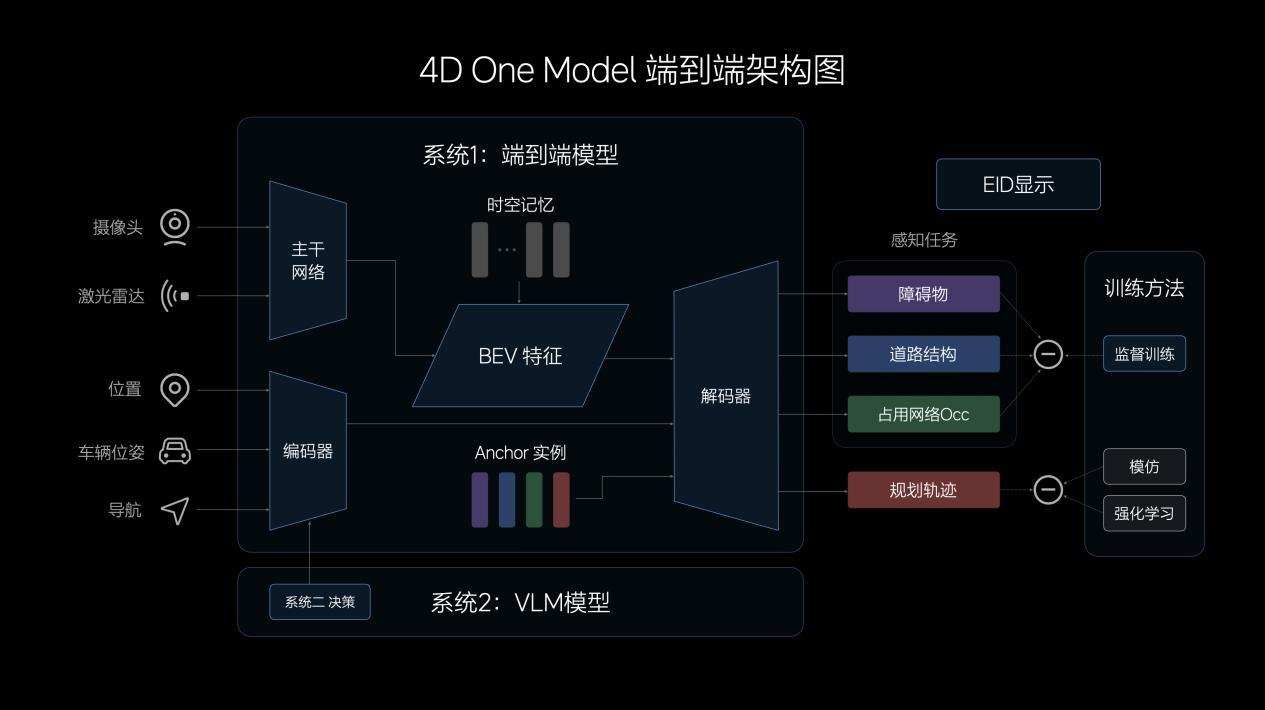
端到端模型的输入,主要由摄像头+激光雷达构成,多传感器特征经过CNN主干网络提取融合,投影至BEV空间。
理想汽车还设计了“记忆模块”,具备时间+空间维度的记忆能力。模型输入中,理想还加入了状态信息和导航信息,经过Transformer模型的编码,结合BEV特征共同解码,得出通用障碍物、动态障碍物及道路结构,规划出行车轨迹。
多任务输出在一体化模型中实现,中间没有多余的规则介入,端到端模型在传递信息、计算推理、模型迭代方面均具有优势。实际驾驶中,端到端模型能够展现出更强的超视距导航能力、道路结构理解能力、通用障碍物理解能力,以及更加拟人化的路径规划能力。
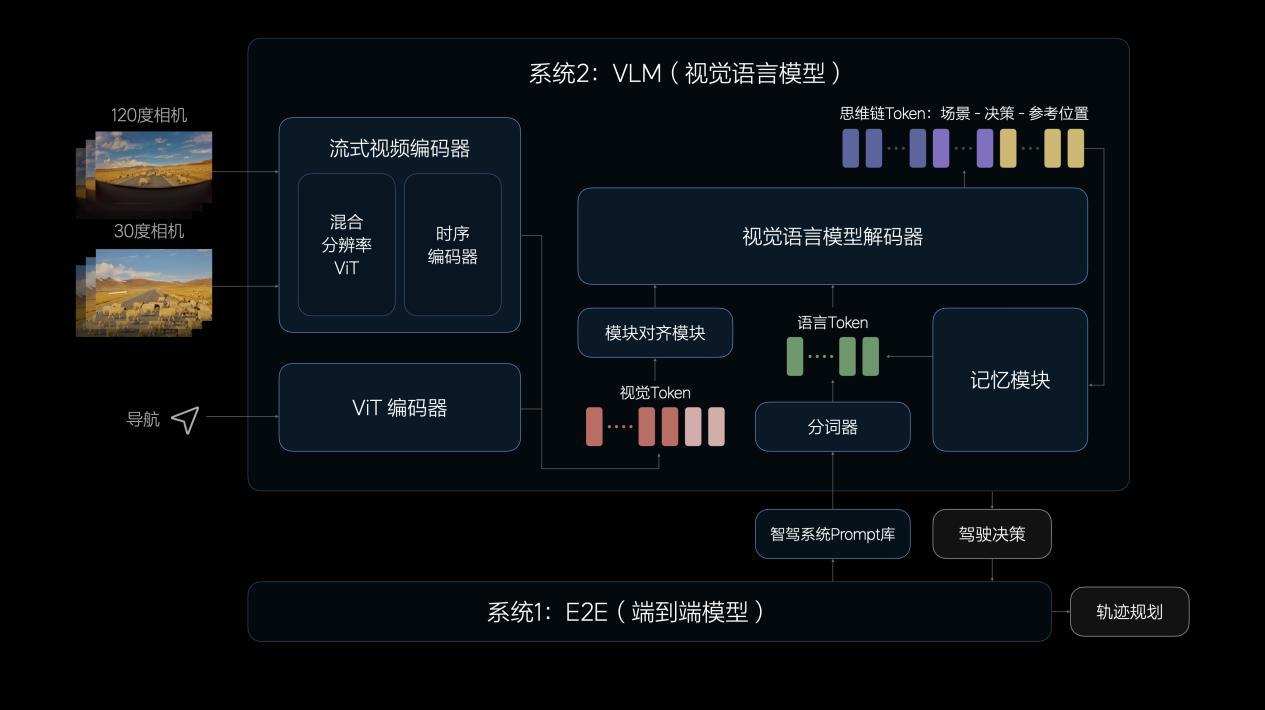
理想的VLM视觉语言模型的参数量达到了22亿,对复杂交通环境有强大的理解能力。
VLM模型能够识别光线强弱、路面平整度等信息,还能够配合车机系统修正导航路线。VLM模型能理解公交车道、潮汐车道等复杂规则,以作出合理决策。
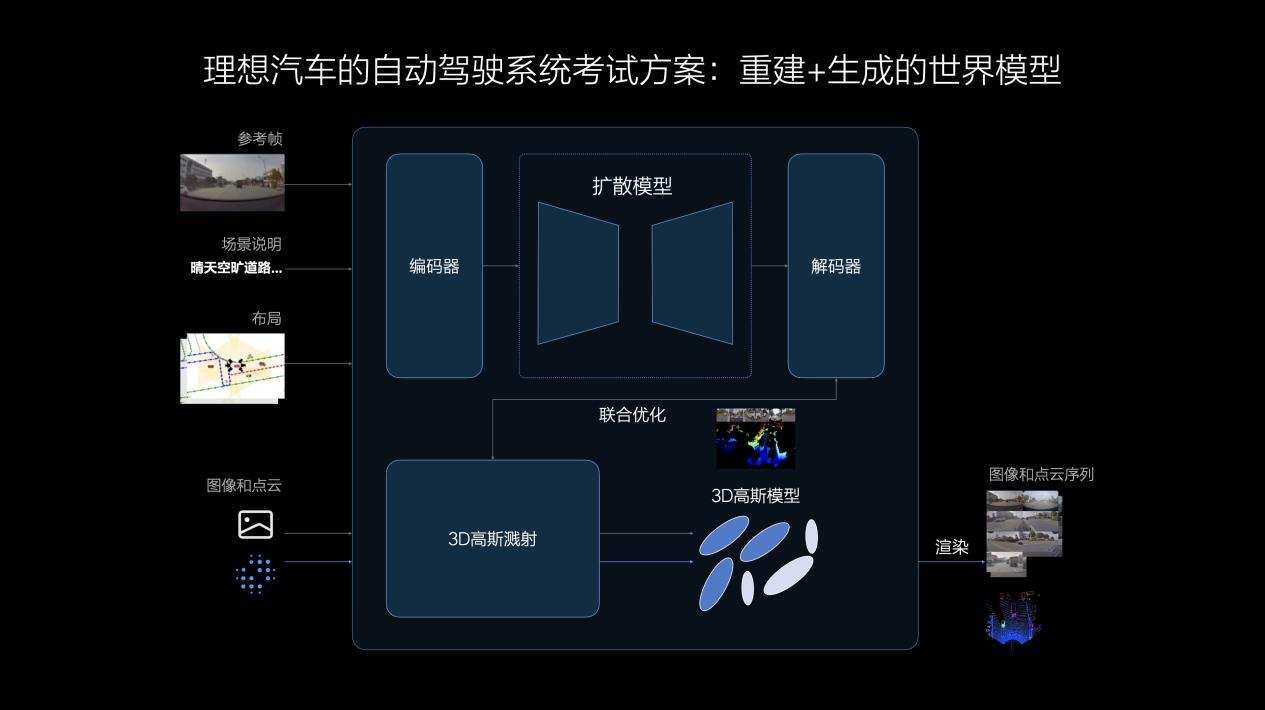
理想的世界模型结合了重建和生成两种技术路径,将真实数据通过3DGS进行重建,并使用生成模型补充新的视角。
场景重建时,动静态要素被分离,静态环境重建、动态物体进行重建和视角生成,经过场景重新渲染形成三维世界。生成模型具有强泛化能力,车流、天气、光照等条件均支持自定义改变,生成符合真实规律的新场景。
重建和生成两者结合所构建的场景,为智驾系统的学习和测试创造了更好的环境,使系统具备高效的闭环迭代能力。
邦点评
自从“自动驾驶”的概念被车企摆上高位,公众对这个技术领域的争议就从未停止。
激进的人群认为,智能科技将以手机淘汰胶卷的姿态改变汽车,而保守的人群纠结于出了问题究竟是车负责,还是人负责。不论如何,人工驾驶或自动驾驶都存在风险,后续自动驾驶的字眼也逐渐淡出视野,普遍已经演化成今天的智能驾驶、智驾等词汇。
以往,智驾是一门烧钱的大工程,从某种程度来说,智驾投资甚至是一家车企的广告费,是抢市场、卷同行的武器。不过智能电动汽车行业已经刮起一股新风,被逐渐纳入主动安全的智能驾驶也越来越具备亲和的一面,相信以后大家越来越不会讨厌智驾这件事。








